HI-Captcha-Image Annotation: HI-Captcha –Crowd sourcing the machine learning training set
We propose to harness the collective knowledge of healthcare providers by developing software which can crowd-source diagnostic image validation for machine learning
Danville, PA United States Diagnostics BigData Hospital Solutions MedStartr Ventures challenge
About our project
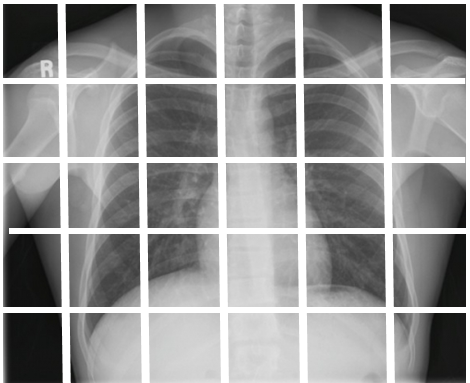
The problem we solve: : Machine learning image analysis requires defining ground truth; a training set is necessary for the deep learning algorithms to learn. There is known variation between experts, with reported inter-observer variability in Radiology and Pathology as high as 15% and 12%, respectively. Variability has prompted institutions to require double reading of images, increasing workload and time. Computer aided diagnosis (CAD) can act as an automated “second check”, reducing the cases needed for review. However, in order to develop accurate CAD, machine learning algorithms need well annotated training sets. The small number of subject matter experts (SMEs) training today’s systems magnifies the issue of variation, and leads to inaccuracies in the “source of truth,” dependent on the expertise of the clinicians who have trained the system. Creating a simpler way for SMEs to annotate images would expand the pool of experts and lead to crowd-sourcing of the training sets.
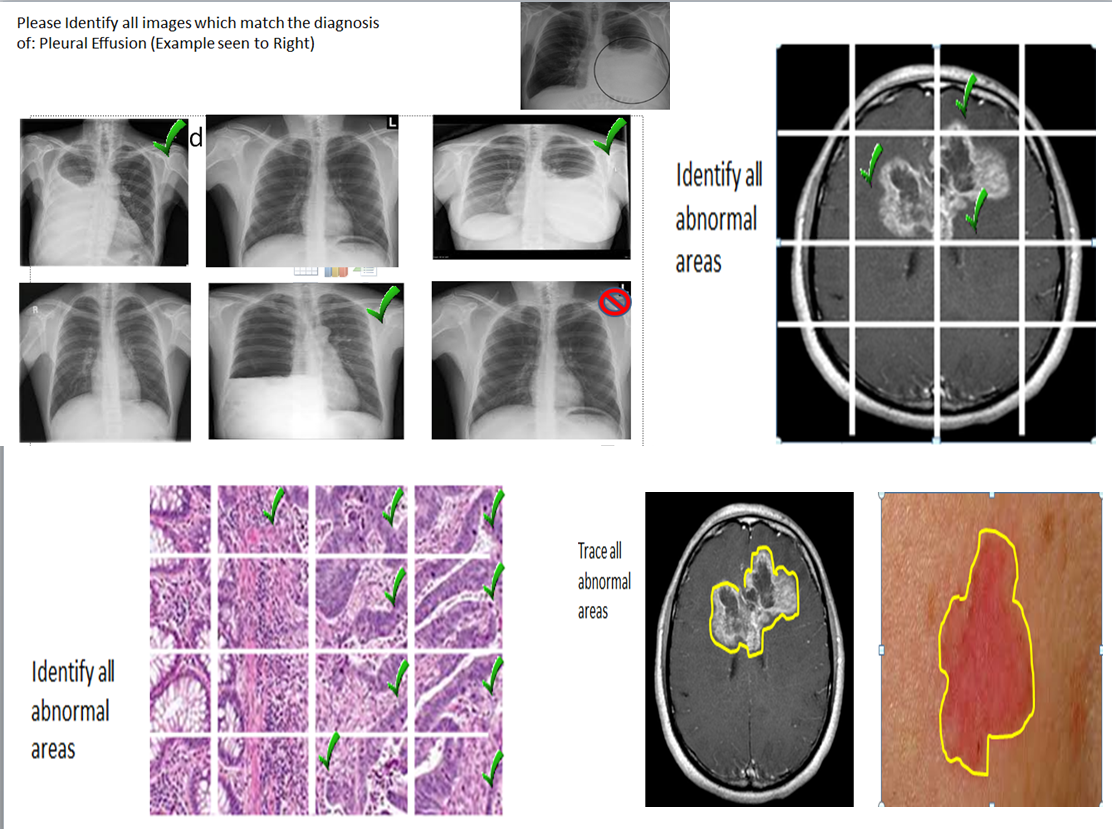
About our solution: Captcha is an open-source security system intended to protect websites by distinguishing between human and machine input. There are several image-based Captchas, such as ESP-PIX and SQ-PIX, which allows users to identify individual parts in an image We propose to utilize the Captcha technology to enable crowd-sourcing of image training sets. Users can quickly identify the areas of interest using the captcha technology. With ESP-PIX, users can identify simple objects such as a heart on an x-ray by choosing the portions of the image that contain the object of interest. In contrast, SQ-PIX allows users to trace a complex object, such as invasive carcinoma on a whole slide image. These techniques can be applied to large image data repositories across multiple institutions, and would enable and encourage crowd-sourcing of the training sets. This would lead to faster validation of much larger data sets, as well as reduce the inherent variability when using small numbers of SMEs.
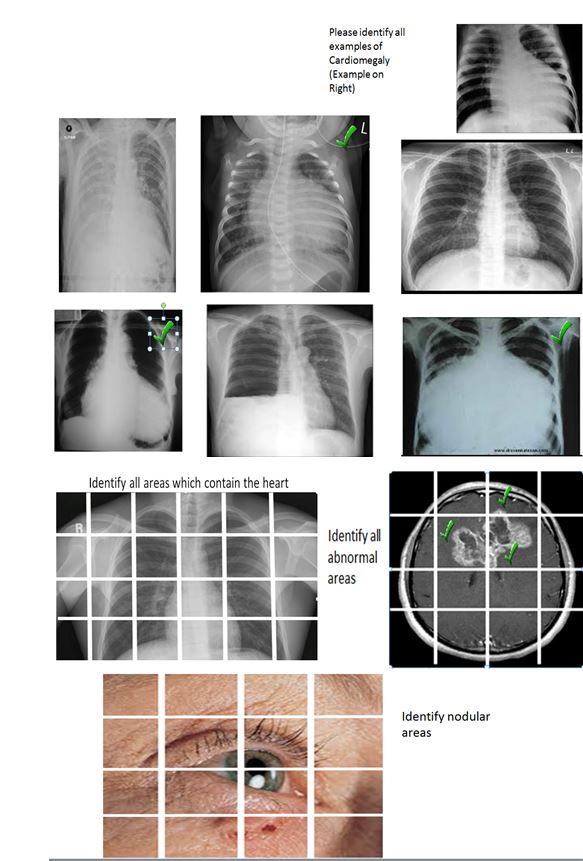
Progress to date:
This project is early in its conception phase, and we are working on a plan for rapid innovative cycles for its development and testing. There is support for this effort within the informatics, pathology and radiology communities at our institution. Geisinger has a unified data architecture (UDA) which is able to ingest a large volume of healthcare images, as well as a Hadoop platform for data warehousing. Currently we have an image repository which contains millions of healthcare images, a portion of which could be annotated as a test case for machine learning techniques using crowd-sourced image-identification techniques. The test case will ask how can HI-Captcha be applied, whether experts easily use it, and do they like using it We believe that utilizing HI-Captcha has the potential to provide relevant images for providers who need verification, as well as rapidly annotate large repositories of healthcare image for eventual evaluation by different machine learning algorithms.
About Our Team

Creator: Chancey Christenson
Education: Tulane University Medical School
Bio: I am a 2nd year Clinical Inforamtics Fellow at Geisinger Medical Center and am interested in Machine learning techniques. I am a Board certified Clinical Pathologist from Tulane University with a Fellowship in Transfusion Medicine from New York Blood Center. Figuring out ways to better teach computers to aid in Computer Assisted Diagnosis is a major goal of mine.
Hospital Affiliation: Geisinger Medical Center
Title: Clinical Informatics Fellow
Advanced Degree(s): MD,MPH
About Our Company
Geisinger Medical Center
Location: 100 N. Academy Ave
Danville, PA 17821
US
Founded: 1915
Product Stage: Idea
YTD Sales: 1M...5M
Employees: 200+
How We Help Patients
As patients, we all want accurate and timely diagnoses, which can guide our health care team to deliver the best care. This basic truth is valid for many diseases and conditions, whether relatively simple or complex. There is an ever-increasing cognitive workload placed upon clinicians, who are asked to see more patients and make more diagnoses in a shorter amount of time. Increasing this workload imposes a human cost in terms of physician fatigue, and represents a potential source of missed or improper diagnosis. Tools that support the clinician by leveraging the power of image analysis and machine learning will provide increased diagnostic accuracy and decreased variability in care Instances of missed, incorrect or incomplete diagnoses will decrease. Patients will benefit from these timely and more accurate diagnoses through more focused treatment options provided more quickly.
How We Help Physicians
A well-developed CAD image analysis system can both prescreen cases to focus the clinician on the diagnostic features of the image, as well as act as an automated second opinion for a clinician, leading to a reduction in both physician workload and diagnostic errors. Perceptual errors occur when an important diagnostic aspect in an image is missed, whether through fatigue and/or lack of experience or knowledge. However, the accuracy and effectiveness of CAD systems require well annotated training sets. Utilizing HI-Captcha with medical images would facilitae the creation and annotation of these training sets through inter-institutional expert crowd sourcing. With Captcha we can have 1000 experts annotate each image, and these images can be aggregated from multiple institutions across the world anonymously to protect patient privacy. This will accelerate the use of automated image analysis of medical images, leading to a reduction in clinician workload, and reducing the frequency of diagnostic errors. This benefits not only the clinicians performing the diagnosis of medical images, but also assists treating clinicans wtith more accurate and timely diagnoses on which to base their treatment decisions.
How We Help Hospitals
Hospitals are increasingly focused on providing the highest quality and efficiency of care. In addition, numerous studies examining decades of malpractice litigation in radiology and pathology demonstrate that the overwhelming majority of these cases involve alleged diagnostic mistakes attributed to perceptual errors and errors in judgement. Image analysis systems that provide diagnostic support to providers can improve diagnostic accuracy and the timeliness of diagnoses while reducing the burden on these diagnostic providers as well as reduce the incidence of malpractice cases related to diagnostic errors. HI-Captcha would facilitate inter-institutional collaboration of images and experts to create the most comprehensive and accurate training sets for computerized image analysis systems. In addition, many current image analysis systems are proprietary, and relatively expensive to implement. Our HI-Captcha solution is based on open-source technology that would lead to reduced costs.
How We Help Partners
There is a tremendous push towards interinstitutional collaboration, especially in the medical research community as well as in the development of new technologies. While large integrated health delivery networks can leverage their size and diversity, smaller health systems struggle in this area. A simple and open source tool such as Captcha image analysis facilitates collaboration between health systems for everyone’s mutual benefit. For example, many institutions have developed biorepositories for research, but it is difficult to identify appropriate specimens for a specific research project, especially across institutions. Better image analysis through Captcha can allow researchers to quickly locate appropriate specimens for study across multiple institutions. Entrepreneurs and start-up companies are constantly searching for health care partners to assist in the development of a concept or product. Captcha image analysis will enable those with a new idea involving the use of images to quickly and easily test their concept. There is also active collaboration amongst and between deep learning experts and healthcare, and this solution will accelerate the collaborations between these groups of experts.
Challenge Mission
Key Milestones Achieved and Planned
Geisinger has a unified data architecture and a Hadoop platform. This provides access to a well established repository of healthcare iamges. If successful with this pitch we propose to create a test case using 150 de-identified images which will be evaluated by a group of 15 physician informaticists and 10 nurse informaticists. We will assess ease of use and accuracy of annotation from the test case. The test case training images will be developed over the next quarter, with test case study to be implemented in the first quarter of 2018.
Our Competitive Advantages
Our product uses existing open source technology, but applies a novel application for healthcare annotation to it. This will enable crowd sourced annotation of large data sets of healthcare repositories. Thus, new stakeholder groups we would like to attract are entrepreneurs and start-up groups which would like access to already annotated training sets of healthcare images on which to test their machine learning algorithms.
Barriers to Entry
Having access to an established image repository for health care images along with acting in an early-mover position will help reduce barriers to market. Ultimately we hope to prove proof of concept and begin multi-institutional collaboration.
Traction, Funding and Partners
Currently Geisinger provides a stipend to the fellows for research. We hope to use the Amia Pitch competition to develop our test case, and from there, approach Big-Data investors such as Google to continue work on the crowd sourced annotation for image analysis.
Innovation Details
Intellectual Property Summary
As the tools we intend to use are open source, we anticipate that our solution would also be available for public use.
Clinical Information
Numerous studies have documented the interpersonal as well as intrapersonal variation that occurs within diagnostic imaging. For Radiology, variation exists within every type of imaging modality. A Pubmed search for “inter-observer+ variation + radiology” reveals 208 review articles. Of these, the following highlight key issues in variation:
- Interpretive Error in Radiology is a good summary of the inherent levels of variation in radiologic images
- Evaluation of the effect of double reporting on test accruacy in screening and diagnostic imaging studies: A review of the evidence demonstrates the importance of double reporting and how it can improve accuracy
- Current artefacts in cardiac and chest magnetic resonance imaging: tips and tricks demonstrates how artefacts can lead to perceptual errors and variation
Digital Pathology is a newer, emerging imaging modality, and thus there are less studies of observer variation. However the following contain important notes on perceptual error and how it can lead to observation variation
- Measuring Errors in Surgical Pathology in Real Life Practice: Defining what does and doesn’t matter helps provide a framework on how to quantiate errors and quality in surgical pathology. By better understanding how errors in interpretation can occur, it can also help refine sources of variation
- Judging Mistakes in Pathology- Res Ipse Non Loquitur proposes to classify errors as a subtype of interobserver variability, in that an individual pathologist is going against group consensus. Thus error can be used as a marker for variability.
- The following are studies which demonstrate how interobserver variability can affect diagnosis[LB1]
- Mod Pathol. 2017 Oct;30(10):1411-1421. doi: 10.1038/modpathol.2017.59. Epub 2017 Jun 30 PMID:28664936
- Tech Coloproctol. 2016 Sep;20(9):647-52. doi: 10.1007/s10151-016-1513-8. Epub 2016 Aug 13. PMID: 27522597
- Mod Pathol. 2016 Aug;29(8):879-92. doi: 10.1038/modpathol.2016.86. Epub 2016 May 13. PMID: 27174588
Computer Aided Diagnosis (CAD) has the potential to act as an “second set of eyes” for clinicians. It can offer a double check of the image to ensure nothing is missed. Under many current CAD workflows, the clinicians review the image first. The CAD then offers its interpretation, allowing the clinician to review regions of interest they may have missed. The benefit of CAD can be seen here in the following:
- Computer-aided diagnosis in medical imaging: Historical review, current status and future potential provides an overview of how computer aided diagnosis can improve clinical workflow for radiology and pathology
- Both Improvement in radiologists’ detection of clustered microcalcifications on mammograms: The potential of computer aided diagnosis and Improving breast cancer diagnosis with computer-aided diagnosis provide specific examples of how CAD and improve diagnostic accuracy.
- The following summarize the growing importance of CAD for Pathology
- << https://digitalpathologyassociation.org/blog/computer-aided-diagnosis-the-tipping-point-for-digital-pathology/>>
- <https://www.ncbi.nlm.nih.gov/pmc/articles/PMC3132993/>>
- Breast Cancer Res Treat. 2016 Jul;158(1):11-9. doi: 10.1007/s10549-016-3852-6. Epub 2016 Jun 9. PMID:27283833
- Am J Surg Pathol. 2016 Apr;40(4):569-76. doi: 10.1097/PAS.0000000000000574. PMID: 26685085
- J Pathol Inform. 2014 Mar 28;5(1):9. doi: 10.4103/2153-3539.129442. eCollection 2014 PMID: 24843821
- Arch Pathol Lab Med. 2011 Aug;135(8):1010-6. doi: 10.5858/2010-0462-OAR. PMID: 21809992
The problem is that in order to develop robust and accurate CAD algorithms, the machine learning algorithms need well annotated training sets to learn from. These are often created by small groups of SMEs, and in some cases single dedicated researchers. Given the well documented variations within diagnostic observation and the large number of cases needed to create a robust training set, it becomes obvious that the validity of the training set and thus the entire CAD algorithm is entirely dependent on the skill and expertise of individual SMEs using current methods.
Regulatory Status
This project is in the early phase of development. At the current time the FDA has been reevaluating the regulatory mandate for image analysis. While we anticipate no significant regulatory hurdles, we are prepared to pursue formal FDA approval at the appropriate time should it be required.
How we will use the funds raised
The total project development timeline for this prototype development is expected not to exceed 1 year from the award date. We will use the funds to develop test cases to assess the validity of crowd-sourced annotation using Captcha. We will develop several image sets for assessment and annotation by subject matter experts. We will study how they liked using the system, how consistent they were in their annotations, and areas where the different Captcha technologies can be applied. The test cases will also look at which Healthcare image Captcha SMEs prefer, defined by specialty and education. We will also assess ease of use and access. During this trial period we will also explore what regulatory hurdles we may have to address
Thank You
Providing more accurate diagnoses is a goal on which we can all agree. Combining the power of image analysis, machine learning, expert crowd sourcing, and informatics can provide us the correct diagnosis more quickly and efficiently. Adapting and utilizing already available tools such as Captcha will allow us to achieve our goals without having to “reinvent the wheel.” Your support will allow (us to demonstrate the power of combining already existing technologies and expertise to achieve our vision of more accurate and timely diagnoses. Thank you for your serious consideration!
Updates
No updates found .
Supporters
-

11/07/2017 - Liked the project.
10/28/2017 - Liked the project.
10/28/2017 - Liked the project.
10/28/2017 - Followed the project.
10/27/2017 - Liked the project.
10/27/2017 - Followed the project.-Zhang DO, MMSc.jpg)
10/27/2017 - Liked the project.
10/27/2017 - Liked the project. , MD, MSc
, MD, MSc
10/27/2017 - Followed the project.
, MD, MSc
10/27/2017 - Liked the project.
10/25/2017 - Liked the project. Instant Feedback
Instant Feedback
Help us find best new ideas to fund by telling us what you think. Your feedback goes straight to the team behind this project in private, so tell them what you really think.
62Medstartr
Index Score62
Interest
Score0
Adoption
Score11
Likes0
Partners0
Pilots3
Follows-
This campaign has ended but you can still get involved.See options below.
$ 10,000 goal
Instant Feedback
Help us find best new ideas to fund by telling us what you think. Your feedback goes straight to the team behind this project in private, so tell them what you really think.



